
prml第九章
EM算法
期望最大化(EM)算法,是寻找具有潜在变量的概率模型的最大似然解的一种通用方法。
我们希望能对观测变量进行建模,但是我们一般会遇到无法对观测变量直接建模,需要引入隐含变量,用含有隐藏变量的分布来建模。比如说高斯分布是单峰的,虽然很灵活但对多峰分布等情况不能很好的近似,有很大的局限性。但是引入潜在变量变成混合高斯就可以解决他的局限性。考虑一个概率模型有观测变量X和隐含变量Z。他们联合概率分布$p(x,z \vert \theta)$由参数$\theta$控制。我们目标是找一组参数$\theta$使观测到的结果$x$最大。就是要最大化对数似然函数$\ln p(x\vert \theta)$。由于隐含变量Z的存在,我们关于$\theta$最优化$p(x\vert \theta)$一般很困难(涉及到对数里面有求和):
我们引入潜在变量分$q(x)$和Jensen不等式(见prml1.2)lnx是上凸函数有$f(E(x)) \geq E(f(x))$。
ELBO是证据下界(Evidence Lower Bound)。
当$\frac{p(x,z \vert \theta)}{q(z)}$是常数时等式成立。
即得到狭义的EM算法:
选择$q(z)$使下界$ELBO$等于对数似然函数$\ln p(x \vert \theta)$,然后关于$\theta$最大化下界ELBO。得到的新的$\theta$对应的ELBO就能大于旧的$\theta$对应的ELBO,这样新的对数似然$\ln p(x\vert \theta)$大于旧的$\ln p(x\vert \theta)$。从而使对数似然函数变大。
E步骤:
找到$q(z) = p(z \vert x,\theta^*)$
M步骤:
考虑以下分解方法(引入潜在变量分布q(x),想办法凑出上面我们得到的下界):
$KL()$为两个函数之间的KL散度,用来描述两个函数之间的相似性,KL散度一定大于0。(KL散度描述见prml1.2)
相当于ELBO和对数似然之间的距离是$q(z)$和$p(z \vert x, \theta)$之间的KL散度。即对数似然等于ELBO加KL散度。
这样可以得到一般化的EM算法。与狭义的E步骤不同,当我们无法得到$p(z \vert x, \theta)$时,我们可以令已知的分布$q(z)$去逼近$p(z \vert x, \theta)$。即令KL散度最小。
E步骤:
M步骤:
高斯混合模型
高斯混合模型是将多个的高斯分布进行线性叠加的概率模型。他认为得到的数据分为好多类,每一类服从特定均值和方差的高斯分布。他能更好的描述多峰的分布。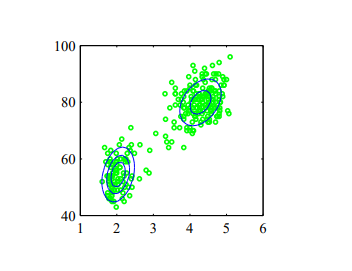
上图可以看到,数据集($x_1,x_2…x_n…x_N$)(绿色数据点)主要聚集成两类,混合高斯模型可以很好的拟合。
假设我们有数据集($x_1,x_2…x_n…x_N$),引入各聚类的均值$\mu_k$和方差$\Sigma_k$。高斯混合模型的边缘概率密度:
引入n个K维的二值随机隐含变量$z_n$,每一个$z_n$中只有一个特殊的$z_{nk}$等于1其余为0。他来描述第n个数据被分为哪一类,若$z_{nk}= 1$则说明第n个数据$\mathbf x_n$属于第k类,$z_n$服从多项式分布。
$z_{nk} = 1$时第n个数据点数据点$x_n$被分为k类,服从$\mu_k,\Sigma_k$的高斯分布。就是说似然函数是:
那么我们可以求到$z$的后验分布:
多维高斯分布有: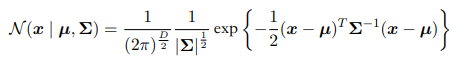
完整对数似然函数是:
C是与参数无关的常数;ELBO为:
对各参数($\mu_k,\Sigma_k$)求导:
对$\mu_k,\Sigma_k$求导会遇到二项式求导的问题:
用上面得到的结论:
$N_k = \sum_{n= 1}^N q(z_{nk} = 1)$;对$\Sigma_k$求导时,会遇到对行列式求导的问题:
求矩阵行列式
$C_{ij}$是矩阵$A$元素$A_{ij}$的代数余子式;我们知道$A$的伴随矩阵是由$A$各元素的代数余子式构成的。即:
所以有:
即
若$A$可逆有$A^* = \vert A \vert A^{-1}$
同时还会遇到以下导数:
要求这个需要先引入对$A^{-1}$的导数:
$I_{ij}$是一个n*n矩阵只有第$i$行第$j$列是1,其余位置是0。可以看图理解: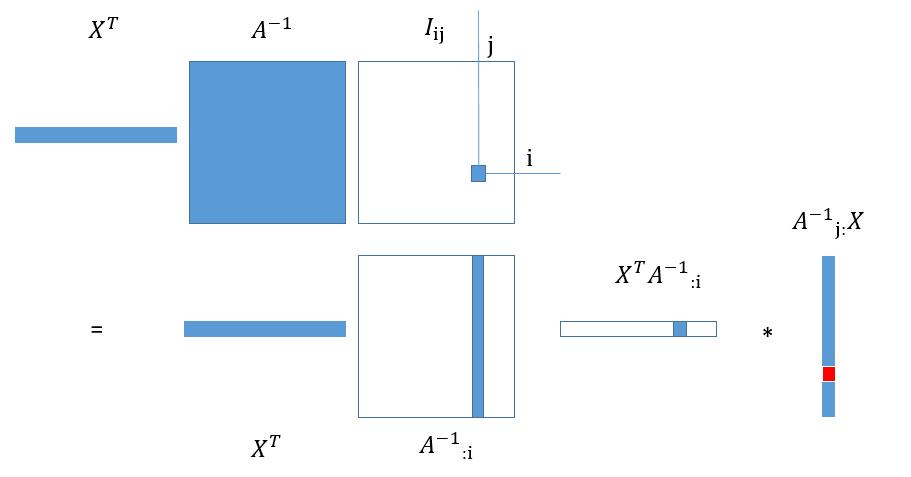
然后我们要扩展成对矩阵求导(将上述两向量交换相乘顺序,既可以得到导数矩阵的转置):
运用上述结论,即可以得到:
对$\pi_k$最大化需引入$\sum_k \pi_k = 1$的限制条件,用拉格朗日乘数法进行优化。
其中有$N = \sum_k^K\sum_n^{N}q(z_{nk} = 1)$。
这样我们就可以得到EM算法用于高斯混合模型的具体流程:
E步骤:
计算旧参数对应的后验分布q:
M步骤:
更新参数:
其中:$N = \sum_k^K\sum_n^{N}q(z_{nk} = 1)$,$N_k = \sum_{n= 1}^N q(z_{nk} = 1)$
笼统地说,这个具体流程像是先确定几个中心点,然后第一步先求各个数据点属于每一类的概率,再以这个概率为权重求均值和方差,让数据点来更改中心点,就这样一步步迭代最后给各数据点聚类(这里的聚类用概率来表示,不是说这个数据点属于哪一类,而是说数据点属于各类的概率,是一种”软”聚类。),并得到与数据点拟合的高斯混合概率模型。
k均值聚类
假设有数据集($x_1,x_2…x_n…x_N$),同时引入k个聚类中心$\mu_k$,k均值聚类目的是令以下J最小:
$r_{nk}$是分类的指示器,$r_{nk} = 1$证明数据$x_n$属于$k$类。
他的迭代方法也类似与EM算法两部分,只是他的后验概率比较特殊。
E步骤:
M步骤:
更新参数
K均值聚类其实是一种特殊的高斯混合模型。他将方差矩阵固定设置为$\epsilon I$,并让$\epsilon \to 0$。这样后验分布就变成:
$\epsilon \to 0$时,相当于给$\vert\vert x_n - \mu_k \vert\vert^2$乘上一个很大的值。假如说$\vert\vert x_n - \mu_j \vert\vert^2 > \vert\vert x_n - \mu_k \vert\vert^2$,稍微大一点就会被$\epsilon$扩大到大很多。然后再求负指数,负指数内值越大,得到的指数就越小。这样$\exp(-\frac{\vert\vert x_n - \mu_j \vert\vert^2}{2\epsilon}) <<\exp(-\frac{\vert\vert x_n - \mu_k \vert\vert^2}{2\epsilon})$。相当于只要$\vert\vert x_n - \mu_k \vert\vert^2$不是最小的,他就会给放的很小直到可以忽略,只有最小的可以留下。这样只有$k = \arg\min_k \vert\vert x_n - \mu_k \vert\vert^2$可以令$p(z_{nk} = 1 \vert x_n) = 1$即第二个等号成立。他的后验概率只能取0和1,相当于每一个样本只可能是某一类。是一种“硬”分类。同时只估计了均值而没有更新方差。
伯努利混合模型
我们考虑一个伯努利分布的混合模型,这种模型也被称为潜在类别分析。数据$\mathbf{x}$是有D个二值变量$x_i$组成的向量,变量$x_i$服从参数为$\mu_i$伯努利分布。即: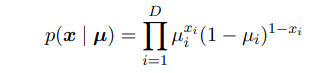
然后我们考虑这种分布的有限混合: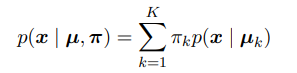
其中$\mathbf{x} = (x_1,..x_D)$,$\mathbf{\mu_k} = (\mu_1,..\mu_i..\mu_D)$
假如我们有一数据集$\mathbf{X} = (\mathbf{x}_1…\mathbf{x}_N)$,那么我们可以得到这个模型的对数似然函数: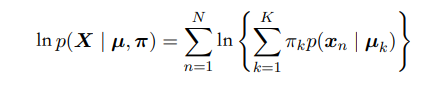
可以看到对数内有求和使得最大似然解没有解析解。与高斯分布相同我们引入n个K维的二值隐含变量$z_n$,每一个$z_n$中只有一个特殊的$z_{nk}$等于1其余为0。他来描述第n个数据被分为哪一类,若$z_{nk}= 1$则说明第n个数据$\mathbf{x_n}$属于第k类。$z_n$服从多项式分布。我们使用EM算法。
E步骤(求后验):
自然可以得到后验:
M步骤(最大化下界):
完整数据的对数似然:
下界:
对各参数求导,或采用拉格朗日乘数法可以得到以下结果。
其中:$N = \sum_k^K\sum_n^{N}q(z_{nk} = 1)$,$N_k = \sum_{n= 1}^N q(z_{nk} = 1)$
我们可以使用伯努利混合模型对二值化的数字图像进行建模后聚类。其中$x_n$就是各二值化后的图像,得到的潜在变量$z_{nk}$的后验概率则为聚类结果。得到的$\mu_k$则可以看作是各数字的图像的概率分布(就是该算法认为的数字长得样子)。