
2333333
模型选择
- 不同的多项式的阶数,不同的正则化参数会产生不同的模型,我们需要预留一些数据用于评估不同模型的好坏。
- 由于过拟合现象,模型在训练集表现并不能表示模型在测试集的表现。数据量大可以使用一部分数据用于评估模型好坏,而数据量小则可以采用交叉验证的方法。但交叉验证会因模型数量变多训练次数会指数型上升。

维度灾难
- 输入变量越多,为描述数据复杂依存关系,不同变量要相乘,使多项式拟合系数数量大幅增加。
- 多维空间的高斯分布的概率质量集中在表⾯附近的薄球壳上。简单来说高维高斯分布
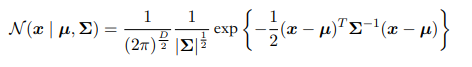
D比较大第一个系数就比较小,需要后面的指数很大才能抵消。故都集中在表面。
决策论
假若我有数据x,想判断他属于Ck中哪一类。
我们之前可以得到$p(x,C_k)$,然后我们需要通过这个概率判断他是哪一类,这就是决策论主题。
- 1.最小化错误分类率
如果$p(x,C_1) > p(x,C_2)$那就把x分到C1类,这样就可以让分类错误的概率最小。
- 2.最小化期望损失
分类错误后产生的后果不同,则最小化错误分类率不一定好。我们假设x属于j类但却分成k类会对我们造成损失$l_{jk}$ j,k相等时损失为0。则我们要最小化。
则就是寻找一个j使得下式最小。
简单来说;假设癌症诊断损失矩阵为((0,1000),(1 ,0))你得到有癌症概率0.1,正常概率0.9你现在判断他是不是癌症就是决策论。最小化错误分类就会分正常。而最小化期望损失分类他会算损失,判断他为正常损失为0.1*1000而判断他为癌症为0.9损失故他会判断他为癌症。
- 3.拒绝选项
引入一个阈值θ,若$p(x,C_1)$小于θ,你就直接避免选择,开摆就完了。
推断与决策
推断就是用训练数据训练出概率模型,分类问题就是推断加决策两个阶段。但你也可以有另外的方法即学习一个函数直接他的输出就是决策。以下为三种方法:
- 1.推断似然函数$p(x \vert C_k)$,然后推断先验概率$P(C_k)$,就可以通过贝叶斯得到后验概率,然后用后验进行决策。这样如果你有Ck可以推出x故又叫生成式模型。
- 2.直接推断后验概率$p(C_k \vert x)$然后决策。为判别式模型。
- 3.找到判别函数$f(x)$直接输入x输出类别,跟概率就没关系了。
越往前越复杂,3虽然简单但由于和概率没关系,前面提到的最小化期望损失和拒绝选项都整不了。
如上述癌症例子,癌症的x光片数据可能远远少于正常的X光片。你把所有都判定为正常都可以有很高正确率,所以这时我们需要对后验概率进行一定修改。使其除以数据集类比例后乘以应用模型目标人群的先验(除以数据集里先验乘上真实先验),然后归一化。这样就可以更好做分类。这时若你用3方法没有后验概率就无法这样。
方法1复杂但可以求$p(x)$来进行异常检测(x概率小但你出现了可能有问题)。同时还可以搞组合模型。X光判断癌症有一个似然$p(x_1 \vert C_k)$血液判断癌症有个似然$p(x_2 \vert C_k)$然后我们知道先验$p(C_k)$就可以通过贝叶斯定理得到$p(C_k \vert x_1,x_2)$从而进行组合模型判断。
回归问题
这部分讲的都是分类问题,回归问题同理,相当于连续的分类问题。将上述求和变为积分最小化期望损失中的损失变为损失函数。其中有一种Minkowski loss期望为: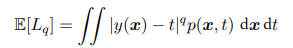
q = 2是平方损失函数,期望最小时y为条件均值,q = 1 是期望最小是y为中位数,q 趋向于 0 期望最小值时y条件众数。
变分法
- 泛函:函数的函数;如上面的期望损失就是找一个$y(x)$使得该值最小。此时该期望损失是$y(x)$的泛函。
假设有一泛函: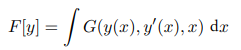
该泛函由多元函数G积分定义,G不仅与y有关还与y的导数和x有关。但由于对x积分则F变成与x无关,与$y(x)$有关。我们给$y(x)$加上微小的扰动$\eta (x)$: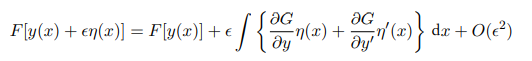
微小的扰动$\eta (x)$在积分边界为0。故可以采用分部积分得到: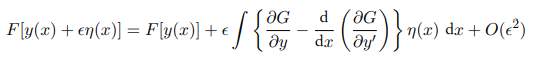
驻点就是给任意微小扰动,泛函值不变。我们可以对比函数中导数的定义: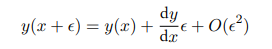
我们就可以得到使泛函F导数为0需要: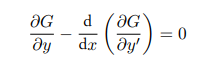
这里其实将对函数求导变成了对变量求导,对于期望损失,我们不需要导数项,仅需要第一项为$ \frac{\partial G}{\partial y} = 0$就可。
回到前面的的期望损失,q = 2时使泛函导数为0有:
故期望最小值为条件均值$E[t \vert x]$。进一步,我们把平方项以下一种方式展开: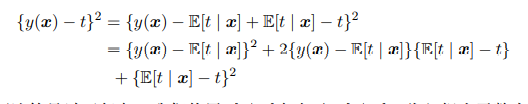
代入原式有: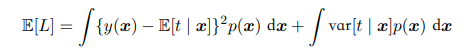
$y(x)$仅在第一项中,而第二项代表的其实是噪声带来的误差,他是不可以减小的,我们只能选择一个好的$y(x)$减少第一项。
信息论
熵
如果有⼈告诉我们⼀个相当不可能的时间发⽣了,我们收到的信息要多于我们被告知某个很可能发⽣的事件发⽣时收到的信息。考虑一个离散随机变量x,当观察到x等于某个值t的时候,我们得到的信息$h(x)$取决于这件事带给我们的惊讶程度。也就是说取决于$p(x = t)$,如果这个概率很大,我们得不到什么信息反之我们会得到很多信息。不相关的x,y的观测一起给我们的信息是$h(x,y) = h(x)+h(y)$而相互独立的两时间概率是$p(x,y)=p(x)p(y)$故我们得到的信息应该为概率的负对数。
上面为一个信息的信息量,平均信息量为:
这里的H叫x的熵(entropy)。
- 均匀分布熵大于非均匀分布
假设x有四种可能状态(a,b,c,d)同等概率下如果概率分别是(1/2,1/4,1/8,1/8) - 熵等于最短的平均编码长度
对于状态(a,b,c,d)我们给出现概率高的状态较短的编码出现概率低的较长的编码就可以使编码长度最短。我们用0表示a,10表示b,110表示c,111表示d
则平均编码长度为
以上是信息论定义的熵,之后采用的熵都是热力学中定义的即将对数改为自然对数。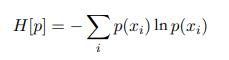
微分熵
我们将离散变为连续。假设在dx区间内$p(x)$几乎不变则在这区间内概率是$p(x)dx$,上式变为:
可以看到当dx无穷小时,熵趋向于无穷,具体化一个连续变量需要无穷比特。第二项跟量化的程度有关而第一项跟概率密度有关。则此时定义微分熵用于描述概率密度信息量:
这个微分熵是$p(x)$的泛函。$p(x)$要满足归一化,一阶矩和二阶矩的限制,我们可以通过拉格朗日乘除法得到最大化微分熵的概率分布是高斯分布。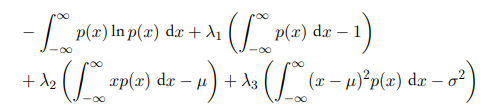
这个式子对$p(x),\lambda_1,\lambda_2,\lambda_3$求导为0。对p(x)求导要用到上面提到的变分法只用看积分内的导数为0: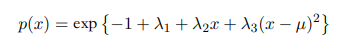
带入限制条件就可以知道$p(x)$是均值为$\mu$方差为$\sigma^2$的高斯分布。
条件熵
假设我们有联合概率分布$p(x,y)$知道了x(即$p(x)$)要求y的话,需要附加条件概率密度$p(y \vert x)$的信息。附加的信息定义为条件熵: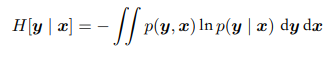
描述x,y的消息等于x的消息加上y对x的条件熵。
相对熵(KL散度)
考虑某个未知的分布$p(x)$,假定我们已经使⽤⼀个分布$q(x)$去近似他。
- 为啥要这样做?
我们有一堆数据x通过真实的$p(x)$生成。我们没办法得到他的解析式。所以需要一个概率去近似他,例如我可以用高斯分布去近似,只需要求出这堆数据的均值和方差,我们就可以用高斯分布近似了。但这样准确吗?不一定准确,可能会丢失一些信息。这时我们还需要附加一些信息,我们附加的信息量(丢失的信息量)称为相对熵即KL散度。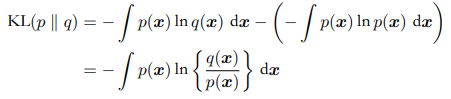
$-\ln q(x)$是$q(x)$所含信息乘上真实概率$p(x)$而不是乘$q(x)$。$q(x)$与$p(x)$恒等时,KL散度为0。KL散度是恒大于0的,可以来表示两个概率相关性。以下为证明:
凸函数性质(下凸函数任意两点间连线在凸函数上面)有: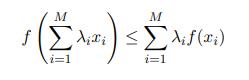
可以把$\lambda_i$看作概率分布,并转变为连续变量,可以得到Jensen不等式: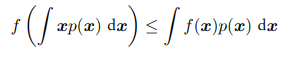
他的另一种写法是:
$-\ln x$是严格下凸函数故有: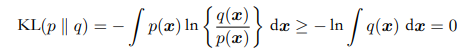
我们可以用kl散度来确定x,y的独立性: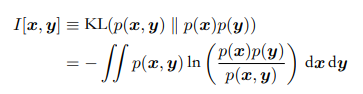
I被称作变量x,y的相互信息,x,y独立I等于0